# first let's import the requests library
import requests HTML and BeautifulSoup
Scraping the web by turning HTML into soup
Tutorial: Parsing HTML with BeautifulSoup
BeautifulSoup is a Python library for pulling data out of HTML and XML files.
This tutorial walks through scraping HTML from a simple kittens webpage. This tutorial is based on lessons by Melanie Walsh’s _Intro to Cultural Analytics, Alison Parrish and Jinho Choi
The official BeautifulSoup Documentation is also a great place to continue searching for that exact feature you want.
HTML Anatomy
Thanks to Alison Parrish, we have a very simple example of HTML to begin with. It is about kittens. Here’s the rendered version, and here’s the HTML source code.
Developer Tools in your browser
First we’re going to use Developer Tools in Chrome to take a look at how kittens.html is organized.
Click on the “rendered version” link above, then launch your browser’s Developer Tools:
- Chrome, Firefox: Right-click (or ctrl-click) anywhere on the page, then click “Inspect”
- Safari: Right-click (or ctrl-click) anywhere on the page, then click “Inspect Element.”
- You may not see this option by default. On the menu bar, go to Safari –> Settings –> Advanced. Check the box “Show features for web developers.” Upon selecting this feature, you should see the “Develop” tab appear in the menu bar. Return to the page and try again.
Your screen should look (something) like this:
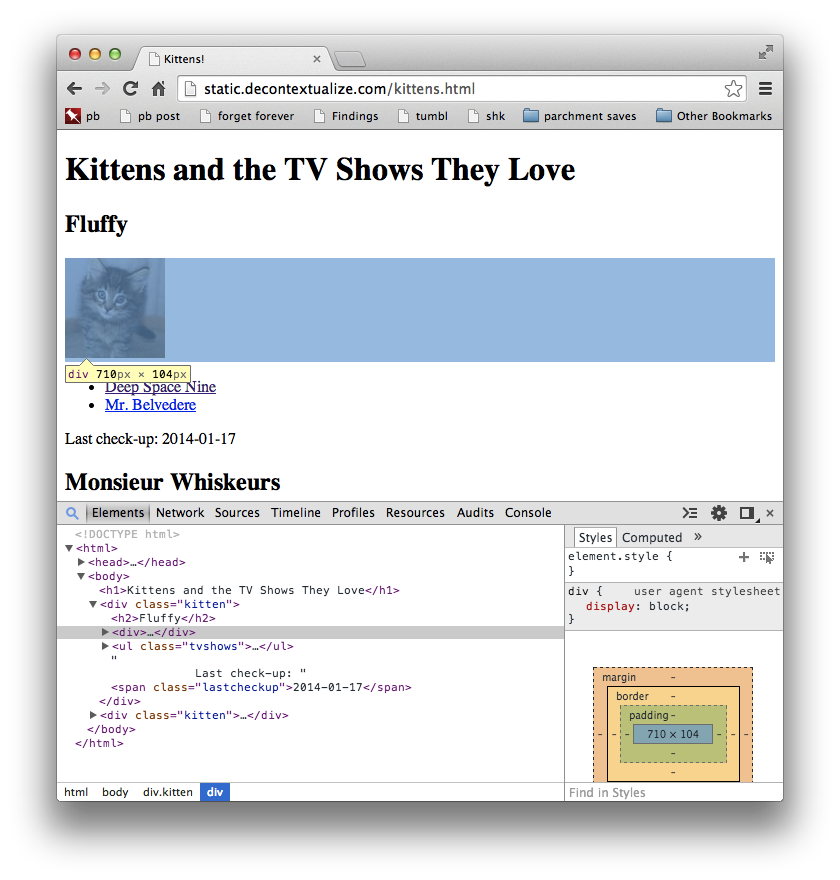
In the upper panel, you see the web page you’re inspecting. In the lower panel, you see a version of the HTML source code, with little arrows next to some of the lines. (The little arrows allow you to collapse parts of the HTML source that are hierarchically related.) As you move your mouse over the elements in the top panel, different parts of the source code will be highlighted. Chrome is showing you which parts of the source code are causing which parts of the page to show up. Pretty spiffy!
This relationship also works in reverse: you can move your mouse over some part of the source code in the lower panel, which will highlight in the top panel what that source code corresponds to on the page. We’ll be using this later to visually identify the parts of the page that are interesting to us, so we can write code that extracts the contents of those parts automatically.
The structure of kittens.html
Here’s what the source code of kittens.html looks like:
<!doctype html>
<html>
<head>
<title>Kittens!</title>
</head>
<body>
<h1>Kittens and the TV Shows They Love</h1>
<div class="kitten">
<h2>Fluffy</h2>
<div><img src="http://placekitten.com/100/100"></div>
<ul class="tvshows">
<li><a href="http://www.imdb.com/title/tt0106145/">Deep Space Nine</a></li>
<li><a href="http://www.imdb.com/title/tt0088576/">Mr. Belvedere</a></li>
</ul>
Last check-up: <span class="lastcheckup">2014-01-17</span>
</div>
<div class="kitten">
<h2>Monsieur Whiskeurs</h2>
<div><img src="http://placekitten.com/150/100"></div>
<ul class="tvshows">
<li><a href="http://www.imdb.com/title/tt0106179/">The X-Files</a></li>
<li><a href="http://www.imdb.com/title/tt0098800/">Fresh Prince</a></li>
</ul>
Last check-up: <span class="lastcheckup">2013-11-02</span>
</div>
</body>
</html>This is pretty well organized HTML, but if you don’t know how to read HTML, it will still look like a big jumble. Here’s how I would characterize the structure of this HTML, reading in my own idea of what the meaning of the elements are.
- We have two “kittens,” both of which are contained in
<div>tags with classkitten. - Each “kitten”
<div>has an<h2>tag with that kitten’s name. - There’s an image for each kitten, specified with an
<img>tag. - Each kitten has a list (a
<ul>with classtvshows) of television shows, contained within<li>tags. - Those list items themselves have links (
<a>tags) with anhrefattribute that contains a link to an IMDB entry for that show.
Summary: HTML Elements
In summary, HTML is composed of HTML elements, which have:
- Tags, provided as the first string within angled brackets.
- (optional) attributes, provided as
attr=valuekey-value pairs within the angled brackets. - (optional) a string and/or other elements under the tag. These will be between the matching angled brackets, e.g.,
<li>and</li>.
You will hear tag and element used interchangeably. This is because every HTML element must have a tag.
TASK: Discussion
What’s the parent tag of
<a href="http://www.imdb.com/title/tt0088576/">Mr. Belvedere</a>?Both
<div class="kitten">tags share a parent tag—what is it? What attributes are present on both<img>tags?
Scraping and Web requests
We’ve examined kittens.html a bit now. What we’d like to do is write some code that is going to extract information from the HTML, like “what is the last checkup date for each of these kittens?” or “what are Monsieur Whiskeur’s favorite TV shows?” To do so, we need to:
- Scrape the HTML from the internet
- Parse the HTML by creating a representation of it in our program that we can manipulate with Python
Let’s do the first task: scraping. It’s left to us to actually get the HTML from somewhere. In most cases, we’ll want to download the HTML directly from the actual web. For that, we’ll use the get method from the Python library requests (link):
If it worked, you won’t get an error message.
Now let’s use the “get” method to make an http request (the eponymous “requests”) to get the contents of kittens.html.
resp = requests.get("http://static.decontextualize.com/kittens.html")
resp<Response [200]>Note that “resp” is a Python object, and not plain text. The HTTP Response Status Code 200 means “OK”—as in, the webpage was able to give us the data we wanted.
Side note: The “get” method makes things easy by guessing at the document’s character encoding. We’re not really going to talk about character encoding until next class, but since we can, let’s check this page’s encoding real quick.
resp.encoding'UTF-8'Okay, back on task. Now let’s create a string with the contents of the web page in text format we use the “text” method for this.
html_str = resp.text
html_str'<!doctype html>\n<html>\n\t<head>\n\t\t<title>Kittens!</title>\n\t\t<style type="text/css">\n\t\t\tspan.lastcheckup { font-family: "Courier", fixed; font-size: 11px; }\n\t\t</style>\n\t</head>\n\t<body>\n\t\t<h1>Kittens and the TV Shows They Love</h1>\n\t\t<div class="kitten">\n\t\t\t<h2>Fluffy</h2>\n\t\t\t<div><img src="kitten1.jpg"></div>\n\t\t\t<ul class="tvshows">\n\t\t\t\t<li>\n\t\t\t\t\t<a href="http://www.imdb.com/title/tt0106145/">Deep Space Nine</a>\n\t\t\t\t</li>\n\t\t\t\t<li>\n\t\t\t\t\t<a href="http://www.imdb.com/title/tt0088576/">Mr. Belvedere</a>\n\t\t\t\t</li>\n\t\t\t</ul>\n\t\t\tLast check-up: <span class="lastcheckup">2014-01-17</span>\n\t\t</div>\n\t\t<div class="kitten">\n\t\t\t<h2>Monsieur Whiskeurs</h2>\n\t\t\t<div><img src="kitten2.jpg"></div>\n\t\t\t<ul class="tvshows">\n\t\t\t\t<li>\n\t\t\t\t\t<a href="http://www.imdb.com/title/tt0106179/">The X-Files</a>\n\t\t\t\t</li>\n\t\t\t\t<li>\n\t\t\t\t\t<a href="http://www.imdb.com/title/tt0098800/">Fresh Prince</a>\n\t\t\t\t</li>\n\t\t\t</ul>\n\t\t\tLast check-up: <span class="lastcheckup">2013-11-02</span>\n\t\t</div>\n\t</body>\n</html>\n\n'That looks like a mess but it’s apparent that we’ve obtained the data as desired.
If we wanted to “pretty print”, note that the html_str has a lot of whitespace: * \t: Tab * \n: Newline
Calling print will render this whitespace in our display.
# pretty print
print(html_str)<!doctype html>
<html>
<head>
<title>Kittens!</title>
<style type="text/css">
span.lastcheckup { font-family: "Courier", fixed; font-size: 11px; }
</style>
</head>
<body>
<h1>Kittens and the TV Shows They Love</h1>
<div class="kitten">
<h2>Fluffy</h2>
<div><img src="kitten1.jpg"></div>
<ul class="tvshows">
<li>
<a href="http://www.imdb.com/title/tt0106145/">Deep Space Nine</a>
</li>
<li>
<a href="http://www.imdb.com/title/tt0088576/">Mr. Belvedere</a>
</li>
</ul>
Last check-up: <span class="lastcheckup">2014-01-17</span>
</div>
<div class="kitten">
<h2>Monsieur Whiskeurs</h2>
<div><img src="kitten2.jpg"></div>
<ul class="tvshows">
<li>
<a href="http://www.imdb.com/title/tt0106179/">The X-Files</a>
</li>
<li>
<a href="http://www.imdb.com/title/tt0098800/">Fresh Prince</a>
</li>
</ul>
Last check-up: <span class="lastcheckup">2013-11-02</span>
</div>
</body>
</html>
Why is web scraping hard?
It turns out that web scraping is heavily restricted on today’s internet. What do you think are reasons why websites would not want programs periodically scraping their data?
In this class, we will usually handle the web requests and scraping for you.
The Beautiful Soup library
Now, onto the next step:
- Parse the HTML by creating a representation of it in our program that we can manipulate with Python.
What representation should we choose? As mentioned earlier, HTML is hard to parse by hand. (Don’t even try it. In particular, don’t parse HTML with regular expressions.)
Beautiful Soup is a Python library that parses (even poorly formatted) HTML and allows us to extract and manipulate its contents. More specifically, it gives us some Python objects that we can call methods on to poke at the data contained therein. So instead of working with strings and bytes, we can work with Python objects, methods and data structures.
Note that BeautifulSoup can parse any HTML that is provided as a string. We’ve already gotten an HTML string from our previous web request, so now we need to create a Beautiful Soup object from that data.
# just run this cell
from bs4 import BeautifulSoup
document = BeautifulSoup(html_str, "html.parser")
type(document)bs4.BeautifulSoupThe BeautifulSoup function creates a new Beautiful Soup object. It takes two parameters: the string containing the HTML data, and a string that designates which underlying parser to use to build the parsed version of the document. (Leave this as "html.parser".) I’ve assigned this object to the variable document.
The document object supports a number of interesting methods that allow us to dig into the contents of the HTML. Primarily what we’ll be working with are:
Tagobjects, andResultSetobjects, which are essentially just lists ofTagobjects.
Finding a tag with find
As we’ve previously discussed, HTML documents are composed of tags. To represent this, Beautiful Soup has a type of value that represents tags. We can use the .find() method of the BeautifulSoup object to find a tag that matches a particular tag name. For example:
h1_tag = document.find('h1')
type(h1_tag)bs4.element.TagA Tag object has several interesting attributes and methods. The string attribute of a Tag object, for example, returns a string representing that tag’s contents:
h1_tag.string'Kittens and the TV Shows They Love'You can access the attributes of a tag by treating the tag object as though it were a dictionary. To get the value associated with a particular attribute. Use the square-bracket syntax, providing the attribute name as key/string.
Get the src attribute of the first <img> tag in the document
img_tag = document.find('img')
img_tag['src']'kitten1.jpg'Note: You might have noticed that there is more than one <img> tag in kittens.html! If more than one tag matches the name you pass to .find(), it returns only the first matching tag. (A better name for .find() might be .find_first(), but we digress.)
Your turn: Find the last check-up date of the first kitten.
NoteSolution
tag = document.find('span')
tag.string'2014-01-17'More on BeautifulSoup
Before we move on:
Beautiful Soup’s .find() and .find_all() methods are actually more powerful than we’re letting on here. Check out the details in the official Beautiful Soup documentation.
When things go wrong with Beautiful Soup
You now know most of what you need to know to scrape web pages effectively. Good job!
But before you’re done, we should talk about what to do when things go wrong.
A number of things might go wrong with Beautiful Soup. Here are just a few.
Tag does not exist with find
You might, for example, search for a tag that doesn’t exist in the document:
footer_tag = document.find("footer")Beautiful Soup doesn’t return an error if it can’t find the tag you want. Instead, it returns None:
type(footer_tag)NoneTypeIf you try to call a method on the object that Beautiful Soup returned anyway, you might end up with an error like this:
footer_tag.find("p")--------------------------------------------------------------------------- AttributeError Traceback (most recent call last) Cell In[23], line 1 ----> 1 footer_tag.find("p") AttributeError: 'NoneType' object has no attribute 'find'
You might also inadvertently try to get an attribute of a tag that wasn’t actually found. You’ll get a similar error in that case:
footer_tag['title']--------------------------------------------------------------------------- TypeError Traceback (most recent call last) Cell In[24], line 1 ----> 1 footer_tag['title'] TypeError: 'NoneType' object is not subscriptable
Whenever you see something like TypeError: 'NoneType' object is not subscriptable, it’s a good idea to check to see whether your method calls are indeed finding the thing you were looking for.
[Out-of-scope material] List comprehension
Consider the following code:
checkup_tags = document.find_all('span', attrs={'class': 'lastcheckup'})
[tag.string for tag in checkup_tags]The second line in the code cell above is a helpful shorthand: it creates a list with each of the tag.strings in checkup_tags.
In more official terms, it’s called a list comprehension, and it helps with a very common task in both data analysis and computer programming: when you want to apply an operation to every item in a list (e.g., scaling the numbers in a list by a fixed factor), or create a copy of a list with only those items that match a particular criterion (e.g., eliminating values that fall below a certain threshold).
A list comprehension has a few parts:
- a source list, or the list whose values will be transformed or filtered;
- a predicate expression, to be evaluated for every item in the list;
- (optionally) a membership expression that determines whether or not an item in the source list will be included in the result of evaluating the list comprehension, based on whether the expression evaluates to True or False; and
- a temporary variable name by which each value from the source list will be known in the predicate expression and membership expression. These parts are arranged like so:
[predicate expressionfortemporary variable nameinsource listifmembership expression]
The words for, in, and if are a part of the syntax of the expression. They don’t mean anything in particular (and in fact, they do completely different things in other parts of the Python language). You just have to spell them right and put them in the right place in order for the list comprehension to work.
You are welcome to use list comprehension in this course, but we won’t test it.
Further reading
- Chapter 11 from Al Sweigart’s Automate the Boring Stuff with Python is another good take on this material (and discusses a wider range of techniques).
- The official Beautiful Soup documentation provides a systematic walkthrough of the library’s functionality. If you find yourself thinking, “it really should be easy to do the thing that I want to do, why isn’t it easier?” then check the documentation! Leonard’s probably already thought of a way to make it easier and implemented a feature in the code to help you out.
- Beautiful Soup is the best scraping library out there for quick jobs, but if you have a larger site that you need to scrape, you might look into Scrapy, which bundles a good parser with a framework for writing web “spiders” (i.e., programs that parse web pages and follow the links found there, in order to make a catalog of an entire web site, not just a single web page).